|
I'm currently a Technical Staff at Alibaba Group, Token Foundry. I received my Ph.D. at the Institute of Automation, Chinese Academy of Sciences and the Beijing Academy of Artificial Intelligence, co-supervised by Prof. Jing Liu and Dr. Xinlong Wang. My research interests span Foundation Models, Native Multimodal Models, Generative Models. |

|
|
|
|
* indicates equal contribution |
|
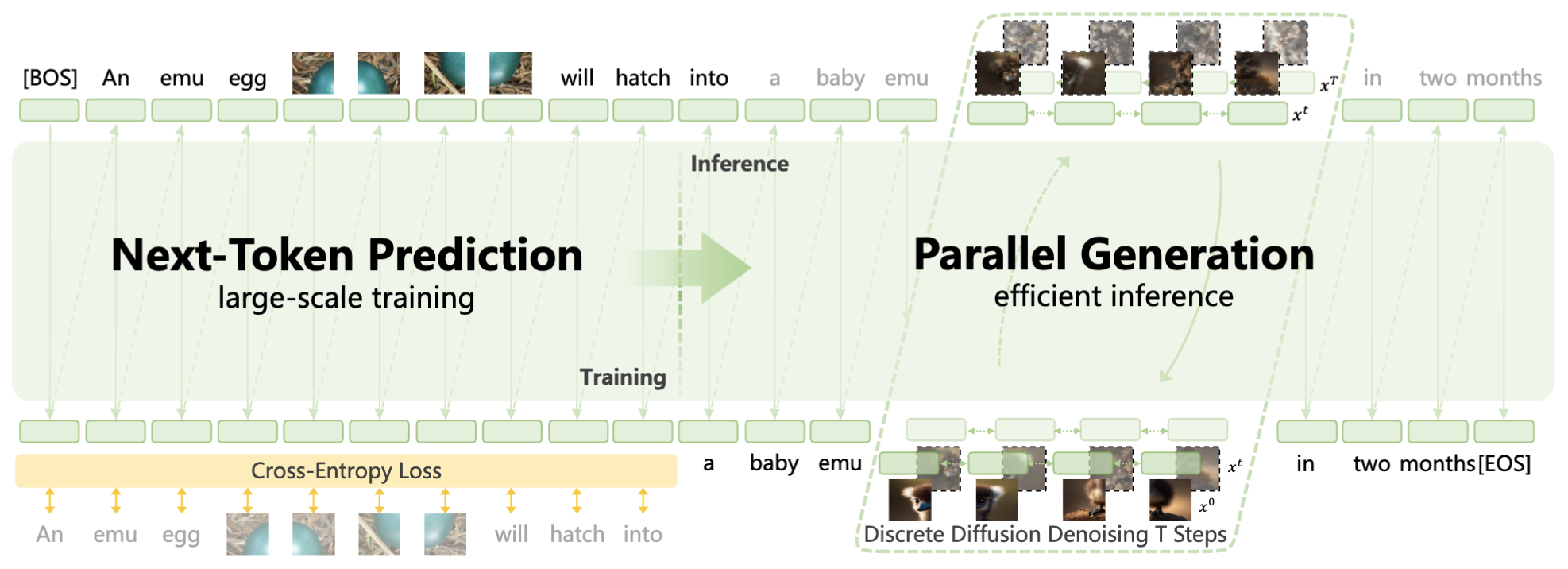
Yufeng Cui*, Honghao Chen*, Haoge Deng*, Xu Huang*, Xinghang Li*, Jirong Liu*, Yang Liu*, Zhuoyan Luo*, Jinsheng Wang*, Wenxuan Wang*, Yueze Wang*, Chengyuan Wang*, Fan Zhang*, Yingli Zhao*, Ting Pan, Xianduo Li, Zecheng Hao, Wenxuan Ma, Zhuo Chen, Yulong Ao, Tiejun Huang, Zhongyuan Wang, Xinlong Wang arXiv, 2025 [Paper] [Page] [Code] a large-scale multimodal world model that natively predicts the next state across vision and language |
|
* indicates equal contribution |

|
Wenxuan Wang*, Fan Zhang*, Yufeng Cui*, Haiwen Diao*, Zhuoyan Luo, Huchuan Lu, Jing Liu, Xinlong Wang NeurIPS, 2025 [Paper] an end-to-end vision tokenizer tuning approach that enables joint optimization between vision tokenization and target autoregressive tasks |
|
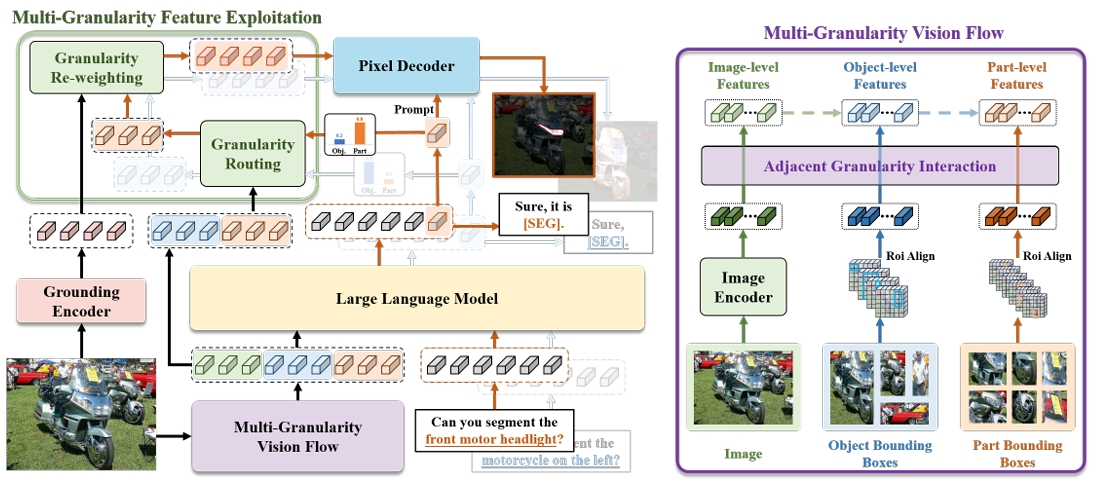
Jing Liu*, Wenxuan Wang*, Yisi Zhang, Yepeng Tang, Xingjian He, Longteng Guo, Tongtian Yue, Xinlong Wang arXiv, 2025 [Paper] takes a step further towards visual granularity unified RES task |

|
Wenxuan Wang*, Zijia Zhao*, Yisi Zhang*, Yepeng Tang, Erdong Hu, Xinlong Wang, Jing Liu arXiv, 2025 [Paper] push towards precisely localizing visual differences based on user instructions |
|
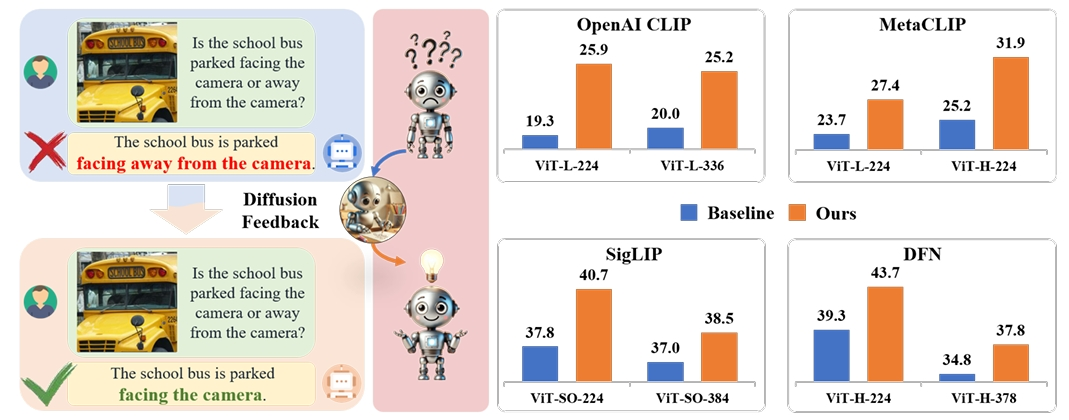
Wenxuan Wang*, Quan Sun*, Fan Zhang, Yepeng Tang, Jing Liu, Xinlong Wang ICLR, 2025 [Paper] [Page] [Code] leverages generative feedback from text-to-image diffusion models to optimize CLIP representations, with only images (without corresponding text) |
|
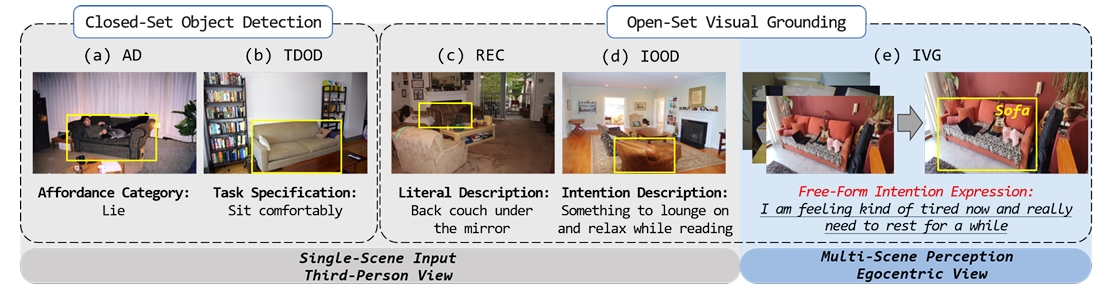
Wenxuan Wang*, Yisi Zhang*, Xingjian He, Yichen Yan, Zijia Zhao, Xinlong Wang, Jing Liu ACL, 2024 (Findings) [Paper] takes a step further to the intention-driven visual-language understanding and promotes classic visual grounding towards human intention interpretation |

|
Wenxuan Wang*, Tongtian Yue*, Yisi Zhang, Longteng Guo, Xingjian He, Xinlong Wang, Jing Liu CVPR, 2024 [Paper] [Page] [Code] takes a step further to finer-grained part-level referring expression segmentation task |
|
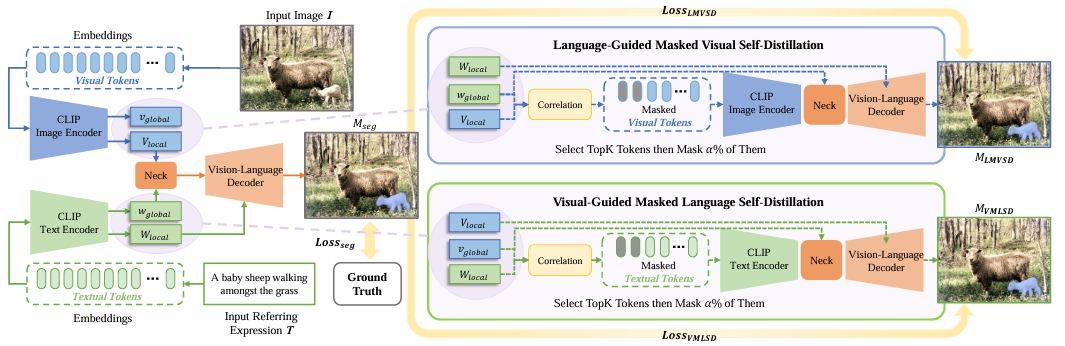
Wenxuan Wang, Jing Liu, Xingjian He, Yisi Zhang, Chen Chen, Jiachen Shen, Yan Zhang, Jiangyun Li IEEE-TMM, 2024 [Paper] a new cross-modality masked self-distillation framework for referring image segmentation task |
|
* indicates equal contribution |
|
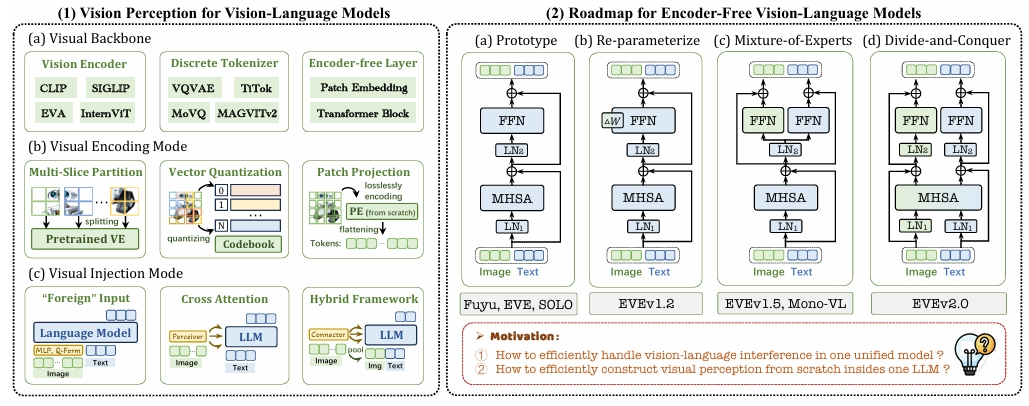
Haiwen Diao*, Xiaotong Li*, Yufeng Cui*, Yueze Wang*, Haoge Deng, Ting Pan, Wenxuan Wang, Huchuan Lu, Xinlong Wang ICCV, 2025 (highlight) [Paper] [Code] encoder-free vision-language models |
|
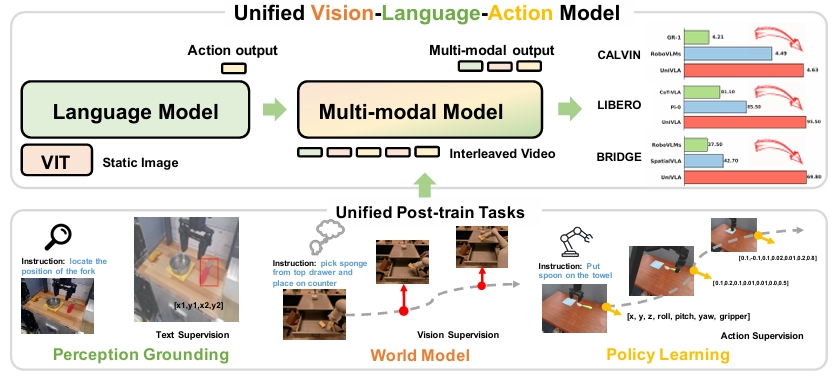
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, Zhaoxiang Zhang arXiv, 2025 [Paper] [Page] [Code] unified vision-language-action model for embodied intelligence |
|
|
|
|
© Wenxuan Wang | Last updated: November 3, 2025