Abstract

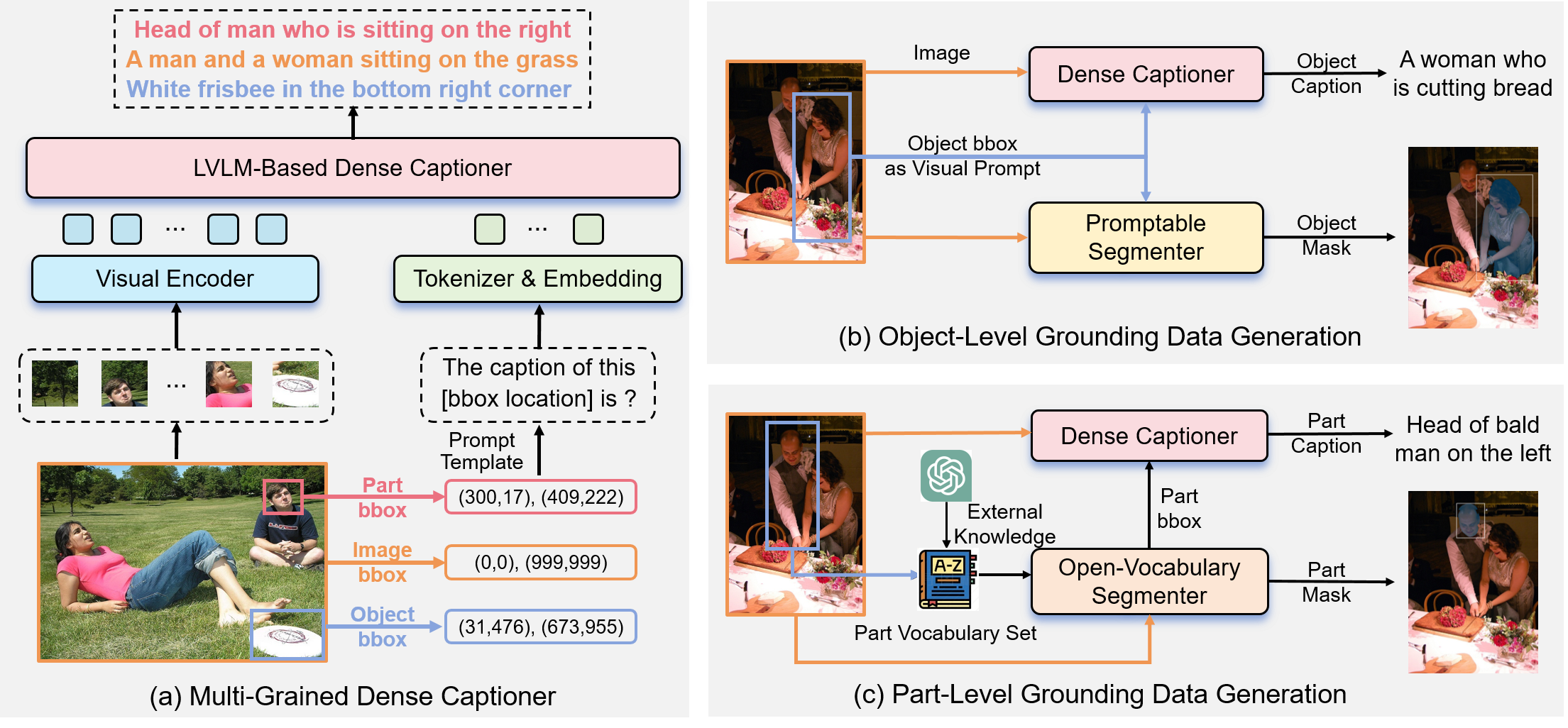
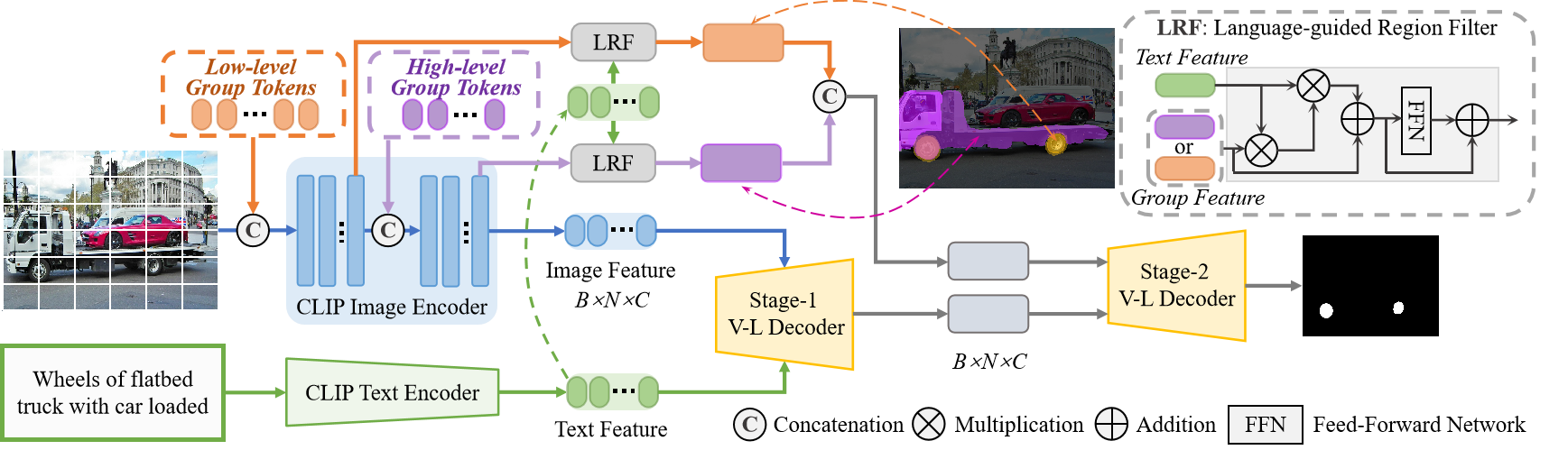
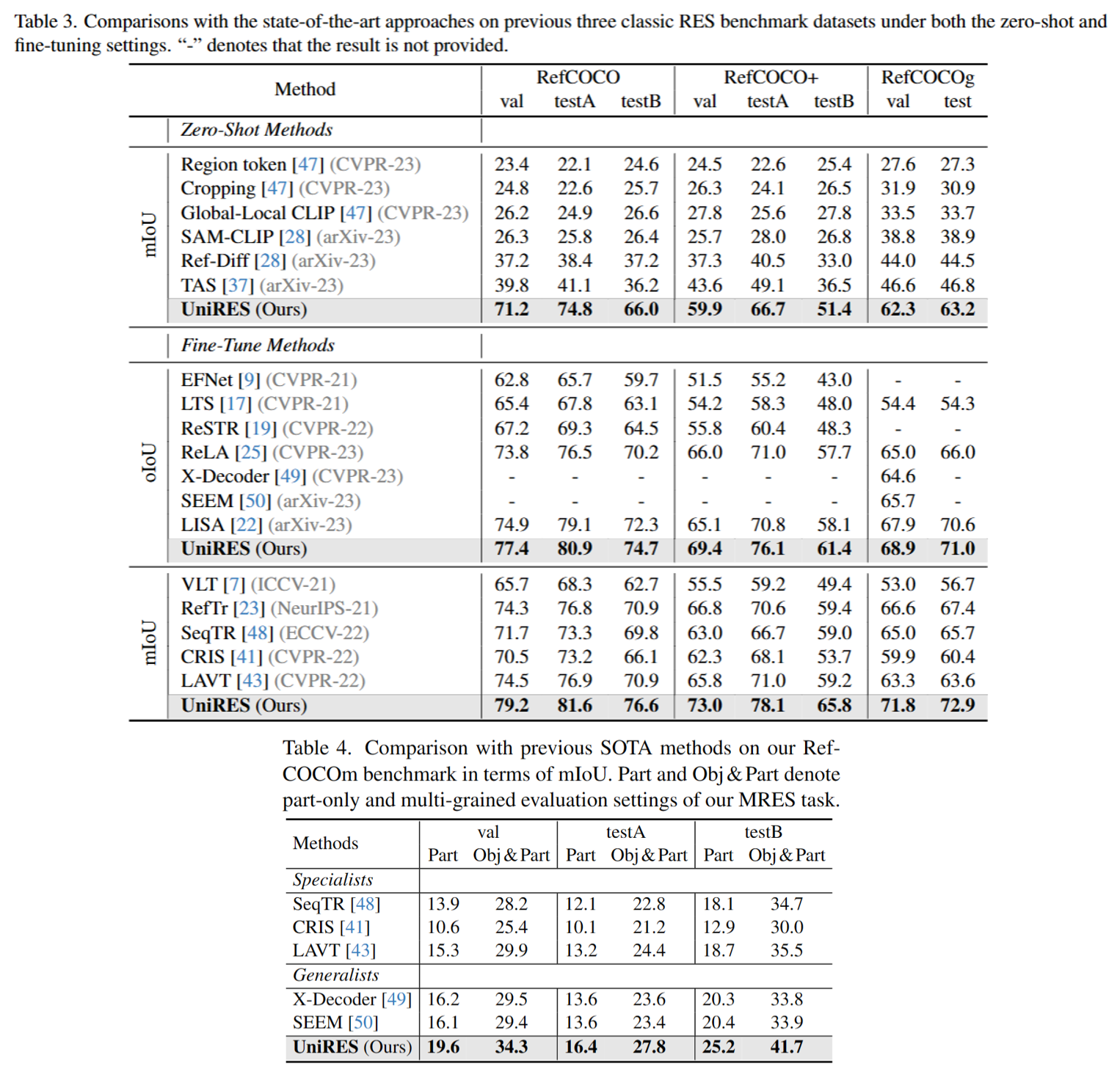
Referring expression segmentation (RES) aims at segmenting the foreground masks of the entities that match the descriptive natural language expression. Previous datasets and methods for classic RES task heavily rely on the prior assumption that one expression must refer to object-level targets. In this paper, we take a step further to finer-grained part-level RES task. To promote the object-level RES task towards finer-grained vision-language understanding, we put forward a new multi-granularity referring expression segmentation (MRES) task and construct an evaluation benchmark called RefCOCOm by manual annotations. By employing our automatic model-assisted data engine, we build the largest visual grounding dataset namely MRES-32M, which comprises over 32.2M high-quality masks and captions on the provided 1M images. Besides, a simple yet strong model named UniRES is designed to accomplish the unified object-level and part-level grounding task. Extensive experiments on our RefCOCOm for MRES and three datasets (i.e., RefCOCO(+/g)) for classic RES task demonstrate the superiority of our method over previous state-of-the-art methods. To foster future research into fine-grained visual grounding, our benchmark RefCOCOm, the MRES-32M dataset and model UniRES will be publicly available.